Test for Normalcy
|
" Every normal person, in fact, is only normal on the average."
~ Sigmund Freud
It is often in our research that we treat our data as though it were normally distributed, and the central limit theorem will often give us good reason. As such, our typical methods for propagating error and determining confidence intervals rely on such an assumption. Therefore, it is important to determine how reasonable an assumption of normality is.
The Quantile-Quantile Plot is means of visually determining how well our data fit a certain distribution. To construct a Q-Q Plot:
- Sort the data, x, in increasing order to create a new vector, xsort.
- Calculate a percentage, Pi, for each sorted datum equal to the its order, i, in xsort divided by the total number of data points, n.
- For each Pi use the inverse CDF function for a normal distribution (or any other distribution of interest) to calculate a value, yi.
- Plot yi verses xsort.
- It is typically useful to fit a line to the middle 60% of the data for comparison (most of the error will inevitably occur near the extreme values).
For an example of a Q-Q plot see the interactive applet at the end of this page.
Skewness and kurtosis are the 3rd and 4th statistical moments and may be used to get a quick idea of your data's normality. The equation for skewness is described here, and kurtosis is described here. For normally distributed data, skew should be 0, as the data should be symmetrical about the mean, and kurtosis, a measure of pointedness, should be 3.
To see how kurtosis and skewness changes with various distributions see the interactive applet at the bottom of this page.
The Anderson-Darling test can quantify a confidence level in the hypothesis that our data are distributed normally. To perform this test:
- Sort the data, x, in increasing order to create a new vector, xsort.
- Find the sample mean, m, and standard deviation, s.
- For each sorted datum, calculate a value, yi, as the normal CDF of xsort with parameters of m and s.
- Calculate an Anderson-Darling statistic:
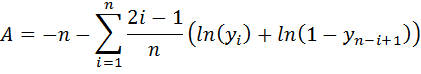
- Correct for small sample sizes:
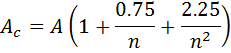
- Calculate the percentage, P, as one minus the Anderson-Darling CDF of Ac. Typically these values are found in tables, as we have no analytical solution for the AD distribution. However, an approximation of the AD CDF can be calculated in and is plotted in the following applet:
Anderson-Darling CDF
x: f(x): 
c
d
f1 0 0 2 x
- If P is less than 5% then then hypothesis of normality is typically rejected.
To see how the Anderson-Darling test changes with various distributions see the interactive applet at the bottom of this page.
Interactive Test for Normality Applet
The following applet shows several tests for normality for data pasted into the text box below or synthetic data. A histogram for the data is plotted and a normal distribution is fitted to the histogram. In the last cell several of the tests for normality discussed above are implemented.
| Enter or paste your data here (comma separated): | Or use synthetic data: | ||||||||||||||||||||||||||
|
|
|
||||||||||||||||||||||||||
| Results: | |||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||
Take note how the Q-Q plot, kurtosis, skewness, and Anderson Darling probability change when you generate synthetic data with a log-normal or exponential distribution, verses the normal distribution.